Exploiting Machine Learning For Improving In-Memory Execution of Data-Intensive Workflows on Parallel Machines
Abstract
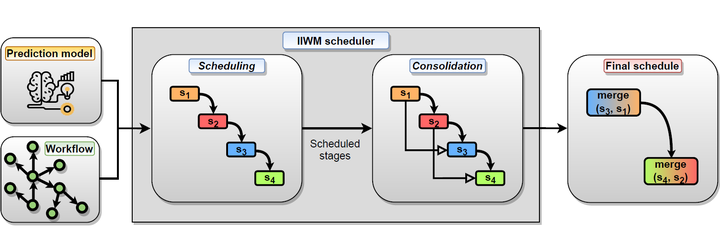
Workflows are largely used to orchestrate complex sets of operations required to handle and process huge amounts of data. Parallel processing is often vital to reduce execution time when complex data-intensive workflows must be run efficiently, and at the same time, in-memory processing can bring important benefits to accelerate execution. However, optimization techniques are necessary to fully exploit in-memory processing, avoiding performance drops due to memory saturation events. This paper proposed a novel solution, called the Intelligent In-memory Workflow Manager (IIWM), for optimizing the in-memory execution of data-intensive workflows on parallel machines. IIWM is based on two complementary strategies: (1) a machine learning strategy for predicting the memory occupancy and execution time of workflow tasks; (2) a scheduling strategy that allocates tasks to a computing node, taking into account the (predicted) memory occupancy and execution time of each task and the memory available on that node. The effectiveness of the machine learning-based predictor and the scheduling strategy were demonstrated experimentally using as a testbed, Spark, a high-performance Big Data processing framework that exploits in-memory computing to speed up the execution of large-scale applications. In particular, two synthetic workflows were prepared for testing the robustness of the IIWM in scenarios characterized by a high level of parallelism and a limited amount of memory reserved for execution. Furthermore, a real data analysis workflow was used as a case study, for better assessing the benefits of the proposed approach. Thanks to high accuracy in predicting resources used at runtime, the IIWM was able to avoid disk writes caused by memory saturation, outperforming a traditional strategy in which only dependencies among tasks are taken into account. Specifically, the IIWM achieved up to a 31% and a 40% reduction of makespan and a performance improvement up to 1.45× and 1.66× on the synthetic workflows and the real case study, respectively.